目前市面上的ChatBI通常使用的是NL2SQL的技术路径,即通过大语言模型直接生成SQL,这种解决方案容易出现数据查询准确率低(准确率在60%-70%,如果跨表查询会更低),数据口径不统一等问题。NL2SQL工具想要落地到真实工程上,需要具备完备 BI能力、极速的交互速度、保证结果的正确性等。
数势科技SwiftAgent在大模型和AI Agent加持下,通过建立业务指标、人货场标签等易于理解的语义层,将自然语言解析到指标和标签语义(Natural Language to Metrics&Label),即可实现相比ChatBI更精准的数据洞察,解决大模型对底层业务语义难理解的问题。此前,数势科技推出SwiftAgent 2.0版本,其在1.0版本基础上做到了五大亮点升级。
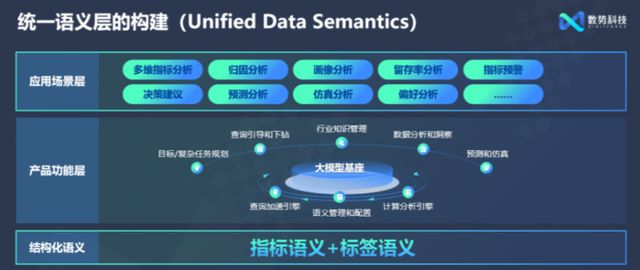
亮点一:统一语义层的构建(Unified Data Semantics)
数势科技SwiftAgent 2.0构建了统一的指标与标签语义层,即Natural Language to Metrics+Label to SQL,实现两段式数据洞察。第一段解决大模型对底层业务语义难理解和幻觉的问题,建立行业标准、指标、人货场标签等易于理解的语义层;第二段解决企业各部门数据口径统一的问题,有效避免数据脏乱差等现象,将传统的经验决策升级为以数据为核心的智能决策。ChatBI通常使用NL2SQL(自然语言到SQL)技术容易出现数据查询准确率低(准确率在60%-70%,如果跨表查询会更低),数据口径不统一等问题。
亮点二:用户可干预(Human in the Loop)
数势科技SwiftAgent 2.0可通过更自然的方式引导用户,如当用户提出“我想看一下最近的销售情况。”这种模糊的数据查询,SwiftAgent会给出“最近7天销售额”、“本月北京地区销售额”等选项,供用户选择,用户还可以根据提示重新提问,最终得到他真正想要看的分析内容。
此外,SwiftAgent 2.0还可以通过用户“点赞”和“踩”的反馈进行强化学习,不断纠正错误、调整查询,从而更懂用户所想所需,也让分析更准确,ChatBI无法了解和正确引导用户的问答方式。
亮点三:持续反思学习(Continued Reflection Learning)
SwiftAgent2.0可将所有使用用户过往的问答分析沉淀到知识库,加上上文提到的强化学习结果,在之后其他用户相似的问询场景中,直接提供结论并提供思考过程。这种不断反思学习的能力,也发挥了大模型最大的特点。随着时间的推移不断进步,SwiftAgent2.0可以变得更加聪明、好用,并更贴近业务需求。
亮点四:多源数据链接(Diverse Data Connection)
SwiftAgent2.0还实现了多源异构的数据接入,不仅能接数仓,还能导入文本、Excel、图片、音视频等非结构化知识,满足全面分析思路。如:“美国数据反映劳工市场有降温迹象,减息预期加强,推动金价上涨,导致黄金ETF产品持仓量持续升高。”
亮点五:数据计算加速引擎 (Hyper Computing Acceleration)
SwiftAgent2.0采用了数势科技独创的数据计算加速引擎,可以实现秒级数据查询,真正实现实时的人机交互。
1)底层选用了StarRocks、Doris等数据分析引擎作为执行引擎,在大宽表查询、跨模型关联查询和物化视图等方面性能更好;
2)结合对数据加工和使用场景进行了一系列优化,提供基于视图的预计算能力和基于预计算结果的查询优化能力;
3)数据虚拟化技术,将数据定义和物理数据(业务)解耦,实现指标/标签灵活加工使用,无需排期开发;
总之,当下ChatBI的解决方式无法解决口径混乱问题,数势科技SwiftAgent在大模型和AI Agent加持下,通过建立业务指标、人货场标签等易于理解的语义层,将自然语言解析到指标和标签语义(Natural Language to Metrics&Label),可以帮助企业管理层及个人更高效准确的获取数据、分析数据,助力科学决策的落地与实施。



