全球计算机视觉顶会 CVPR 2020 上,百度共计有 22 篇论文被接收。这篇 Oral 论文中,百度提出了 ActBERT,该模型可以学习叙述性视频进行无监督视频文本关系,并提出纠缠编码器对局部区域、全局动作与语言文字进行编码。最终在 5 项相关测评任务上取得了 SOTA 结果。
ActBERT 在下游视频和语言任务上,即文本视频片段检索、视频描述生成、视频问答、动作步骤定位等任务上明显优于其他技术,展示了其在视频文本表示方面的学习能力。

论文链接:
现有利用 BERT 训练方式进行视频语言建模一般通过量化视频帧特征的方式,通过聚类离散化将视觉特征转化为视觉单词。但是,详细的局部信息,例如,互动对象,在聚类过程中可能会丢失,防止模型进一步发现细粒度的视频和文字对应关系。本文提出 ActBERT 从配对视频序列中挖掘全局和局部视觉线索和文字描述,它利用丰富的上下文信息和细粒度的关系进行视频 - 文本联合建模,其贡献有三点:
首先,ActBERT 整合了全局动作,局部区域与文本描述。诸如「剪切」、「切片」之类的动作对于各种视频相关的下游任务是有益处的。除了全局动作信息,结合本地区域信息以提供细粒度的视觉提示,区域提供有关整个场景的详细视觉线索,包括区域对象特征,对象的位置。语言模型可以从区域信息中受益以获得更好的语言和视觉一致性。
其次,纠缠编码器模块对来自三个要素进行编码,即全局动作,局部区域和语言描述。新的纠缠编码模块从三个来源进行多模态特征学习,以增强两个视觉提示和语言之间的互动功能。在全局动作信息的指导下,对语言模型注入了视觉信息,并将语言信息整合到视觉模型中。纠缠编码器动态选择合适的上下文以促进目标预测。
此外,提出四个训练任务来学习 ActBERT。预训练后的 ActBERT 被转移到五个与视频相关的下游任务,并定量地显示 ActBERT 达到了最先进的性能。
算法
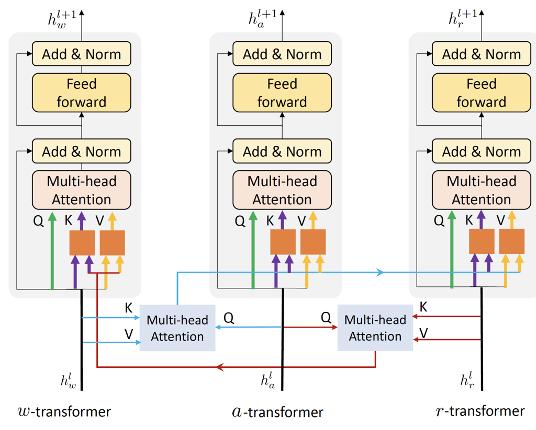
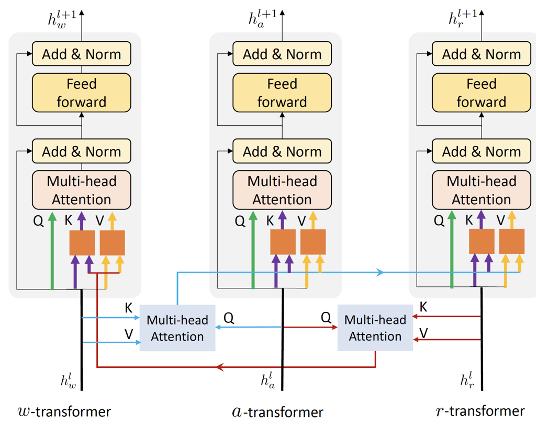
纠缠编码器
纠缠编码器包括三个编码器, 三个编码器的输入来自三个来源。为了加强视觉和语言特征之间的互动,纠缠编码器将视觉信息注入语言编码器,并将语言信息整合到视觉编码器中。具体来说,纠缠编码器利用动作信息催化相互交流。
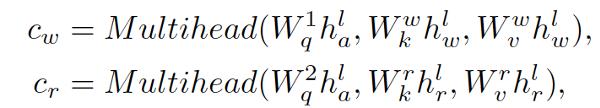
本文提出四个训练方式进行模型学习。第一、有掩码的语言建模任务。本文利用区域物体和全局动作中的视觉信号,发现视觉和语言实体之间的关系。该任务迫使模型从上下文描述中学习,同时提取相关的视觉特征以协助文本预测。当动词被去除时,模型应该利用动作特征来更准确预测。当描述局部的名词被去除时,本地区域特征可以提供更多的上下文信息。
第二、有掩码的动作分类任务。这个任务是根据语言和物体特征,预测被去除的动作标签。明确的动作预测可以有两方面的好处。1)长时期动作序列线索可以被挖掘,该任务可以更好地分辨执行动作时的时间顺序;2)利用区域物体和语言文本可以获得更好的跨模态建模,该任务可以增强预训练模型中的动作识别能力,可以进一步推广到许多下游任务。
第三、有掩码的物体分类任务。在该任务中,局部区域对象特征被随机去除。其目标分布为将该区域输入到相同的目标检测模型得到的激活值。优化目标是最小化两种分布之间的 KL 差异。
第四、跨模式匹配。与下一个句子预测(NSP)任务类似,在第一个符号 [CLS] 的输出后加入了一个线性分类器,用来指示语言与视觉特征的相关性。如果分数较高,表明文本很好地描述了视频剪辑。
实验设置
ActBERT 在 HowTo100M 数据集上进行预训练。该数据集涵盖了总计 23,611 项任务,例如维护和修理、动物营救、准备食材等。在五个任务上评测了 ActBERT 的性能。
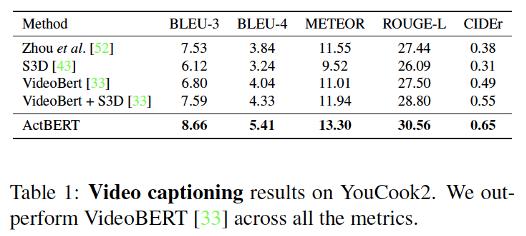
视频描述生成实验结果
动作分割实验结果
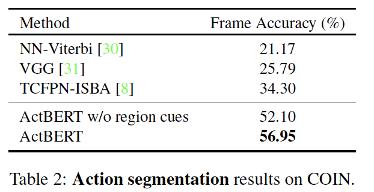
动作步骤定位实验结果
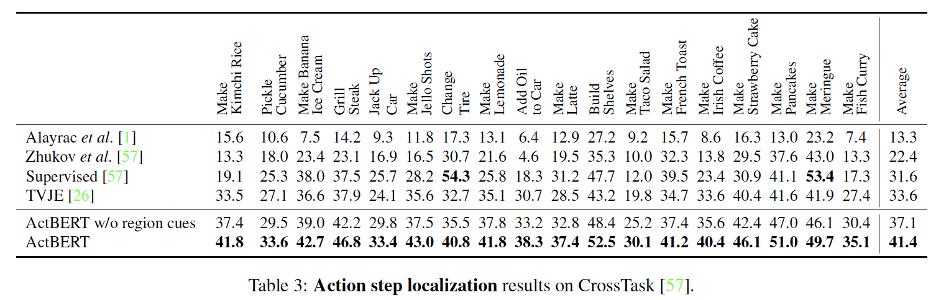
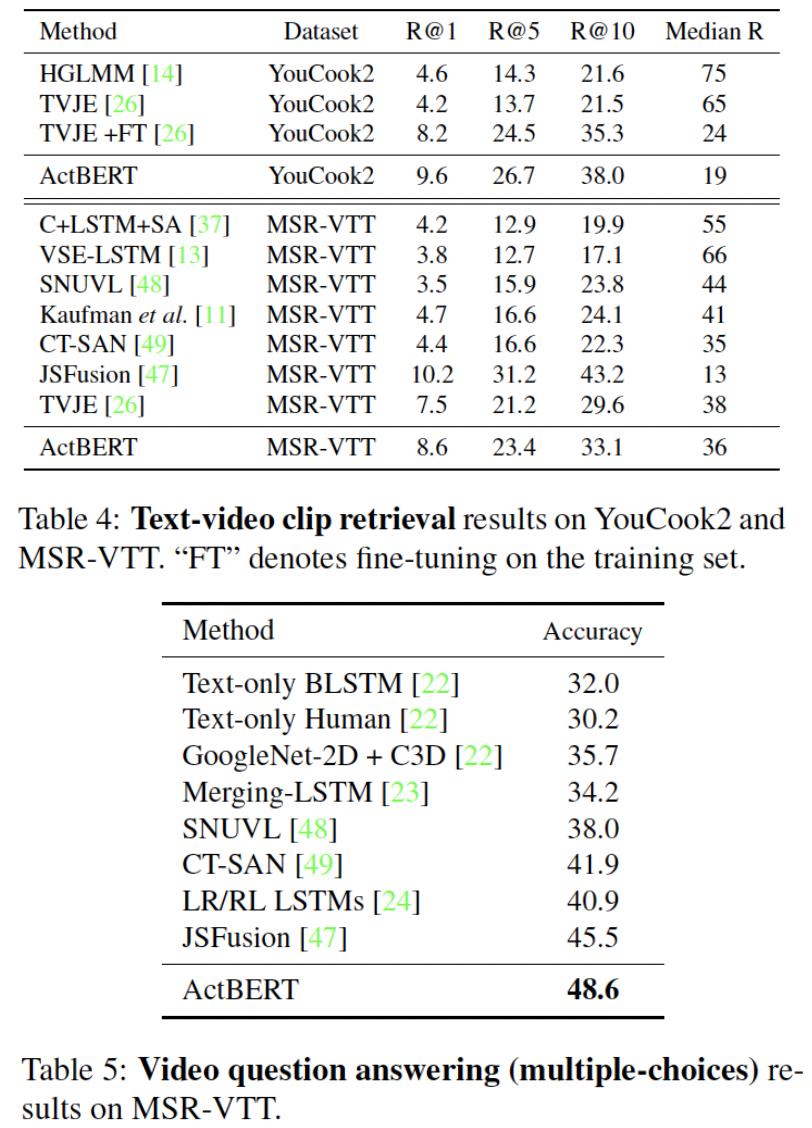
文本视频片段检索与视频问答实验结果
结论
ActBERT 以一种自我监督的方式进行联合视频文本建模。该方法直接为全局和局部视觉信息建模,以进行细粒度的视觉和语言关系学习。ActBERT 将信息的三个来源作为输入,并使用了新颖的纠缠编码器进一步增强三个源之间的交互。五个视频文本基准测试的定量结果证明了 ActBERT 的有效性。未来可以通过设计更强大的视频和文本学习模块来提升 ActBERT,并将其应用到视频动作识别和检测中。
参考文献:
Linchao Zhu, Yi Yang, ActBERT: Learning Global-Local Video-Text Representations, CVPR 2020.
Antoine Miech et al., HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips, ICCV 2019.
Chen Sun et al., VideoBERT: A Joint Model for Video and Language Representation Learning, ICCV 2019
Linchao Zhu, Zhongwen Xu, Yi Yang, Bidirectional Multirate Reconstruction for Temporal Modeling in Videos, CVPR 2017.
本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
原标题:《刷新五项SOTA,百度ActBERT:基于动作和局部物体的视频文本特征学习模型》



