过去的一周,你心情咋样?

除了股票基金过山车般的涨跌之外,工作例会上,你使用的数据PPT模板让展示更加美观有趣,获得老板好评。
一把游戏结束,系统自动送上战力统计,你的队友明显拖了后腿,下次不要和ta组队了。
此时手机又提醒你视屏时间过长,建议休息一下,因为科学研究表明,连续视屏超过x小时便会使视力下降y%……
我们信任数据,认为数据总是客观情况的客观反映。可事实真的如此吗?
2018年,复旦大学开设了一门新的通识课程,邀请学校多个专业的教授对学生每天可能接触到的信息进行“真伪鉴定”,向学生阐述什么是“伪科学”,一经开课便节节爆满。
这门名叫“似是而非”的新课并非复旦大学首创,它的灵感来源于美国华盛顿大学的“拆穿胡扯”(Calling Bullshit)公开课。

这门课由生物学教授卡尔·伯格斯特龙和信息学副教授杰文·韦斯特联合主讲,他们从逻辑和传播渠道的角度揭开数据伪科学如何产生与传播。课程信息一挂在官网就被抢光名额。
这两门课如此火爆,原因是相同的:识别数据陷阱,已然成为当代生活的刚需。数据信息真的可以为“伪科学”操控,虽然我们已经能够识别出披着“震惊×××”外衣的老式胡扯,但它们分裂出来的新亚种令人眼花缭乱。
伯格斯特龙和韦斯特将这些把戏统称为“胡扯”,这门教大家识别并指斥胡扯的课程广受好评,讲义的衍生书籍保留了课程辛辣的原名,中文版便是《拆穿数据胡扯》。
何为胡扯?
那么胡扯到底指什么呢?
作者伯格斯特龙和韦斯特认为:
胡扯就是全然不顾事实、逻辑连贯性或实际传递的信息,而是利用语言、统计数字、数据图表和其他表现形式,通过分散注意力、震慑或恐吓等方法,达到说服或打动听话人的目的。
数据胡扯的最终目的,是通过有意为之的操作,使本应该客观的数据,为己所用。
我们暴露在胡扯面前的时间和机率可能远远超过我们所认为的,形式也是五花八门。
胡扯的视觉把戏
“大鸭子”是一个养鸭户于1931年建造的鸭子形商店,如今已经成为一个受人喜爱的地标。

“大鸭子”,位于美国纽约长岛佛兰德斯
但是作为一座建筑,大鸭子并没有什么特别的功能。在建筑理论中,它已经成为形式优先于功能的标志,“鸭子”也由此成了装饰超过用途的建筑的代名词。
相似地,形式大于数据的图形就可被称为“鸭子”。

《今日美国》是制造数据可视化“鸭子”的先驱之一。上图显然可以代表《今日美国》的风格。
下面这个图形的设计者用两个餐叉的尖齿代表条形图中的条形。
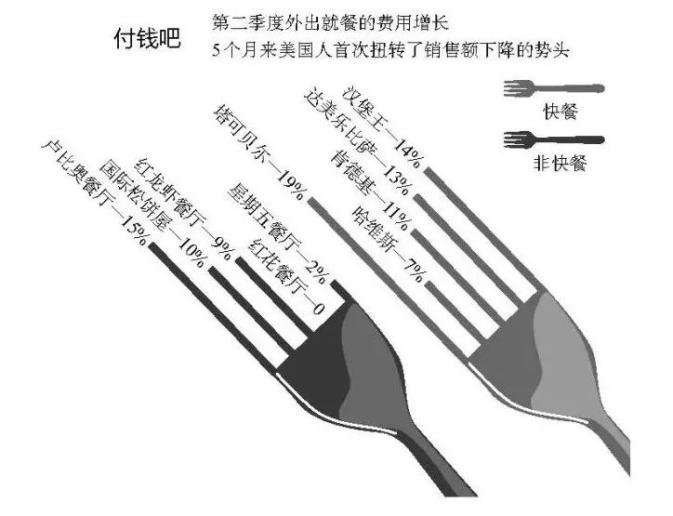
这样做有什么坏处呢?坏处很多:
条形是图形中承载信息的部分,但它们在这张图中只占了很小一部分空间;
倾斜的角度也会引发争议,因为我们不习惯解读这种角度的条形图;
两把餐叉并排,但底部水平线并没有对齐,容易造成错觉;
幸好数值被写出来了。但如果必须依靠数值来解读图形,为什么不直接用表格避免前三个坏处呢?
我们说胡扯就是公然无视事实和逻辑连贯性,企图通过分散注意力、震慑或恐吓来说服或打动受众。
但可爱有什么不对吗?其实“鸭子”真正让我们担心的原因在于,试图装得可爱会让读者更难理解它表示的数据,逐渐变成胡扯。
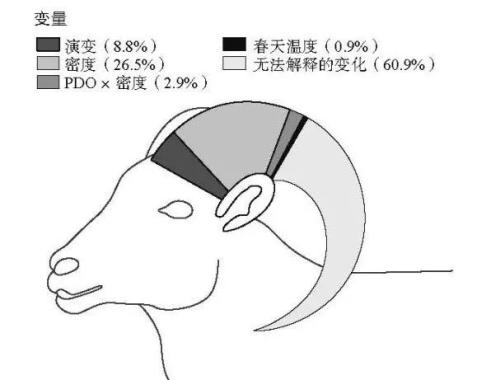
比如这张图,创意可嘉,但是把一个饼形图扭曲成羊角,只会在读者对这些数量进行视觉比较时增加难度。
数据可视化的“鸭子”只是有胡扯的影子,那么被我们称为“水晶鞋”的那一类数据可视化就是完美的胡扯。
“水晶鞋”是将一种类型的数据硬套上用于展示另一类数据的视觉形式。这样做的目的是借用好的可视化形式的权威性表现自己的权威性,完全不考虑数据本身与形式的兼容性。
就像格林兄弟的原版《灰姑娘》故事中,继姐为了穿上水晶鞋切掉了脚趾,削平了脚后跟。
其中最被滥用的形式之一就是地铁线路图,它甚至引发了元层级的评论——“以地铁线路图作为象征的地图的地铁线路图”。
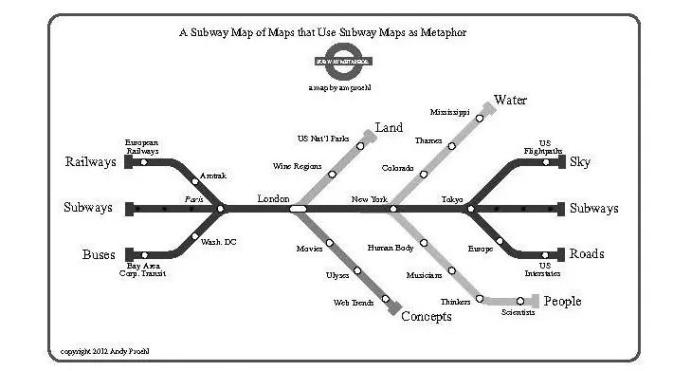
以地铁线路图作为象征的地图的地铁线路图
另一种流行的图表形式是带标签的示意图。这种图的“重灾区”之一,就是PPT。
谁没用过几个看起来丰富、有趣又清晰的PPT模板呢?或者自创一些可爱的模型,就像这只独角兽。
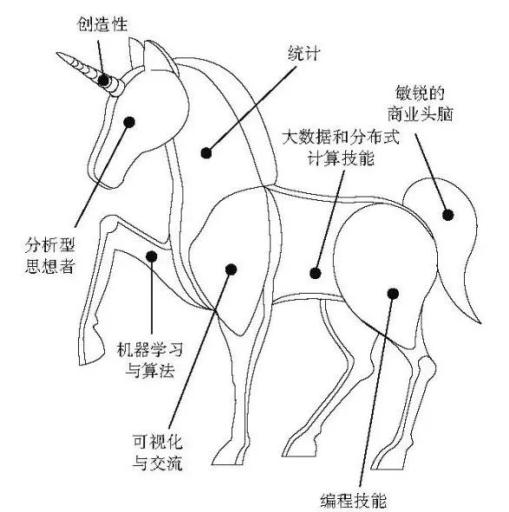
然而图表上的标签毫无道理可言。前肢与“机器学习”和“可视化”有什么关系?为什么“R编程”与后腿有关呢?右后腿为什么没有加标签?为什么头部的“分析型思想者”指的是一种人,而身体的其他部分指的是技能?……
扭曲的数字黑箱
如果我们给“鸭子”们“拔毛”,让数据赤裸裸地呈现在我们眼前,是不是就可以规避掉胡扯了?一定意义上是的,但不绝对。因为还存在着另一种更加隐形的欺诈——数据的来源本身。
当科学家测量元素的原子质量时,这些元素不会密谋增加自己的重量,以便把自己在元素周期表上的位置悄悄往后挪一点儿。
顺便说一句,元素周期表也是一款常用“水晶鞋”
但是,管理者往往会有所体会——当他们衡量员工的工作效率时,员工往往会在量化数据上做文章,以让工作表现更好看一些。
我们在很多领域都能看到这个现象。
当汽车销售人员按达成的销售额获得奖金时,他们就会为客户提供更大的折扣,以便快速完成销售额;而当销售数量成为目标时,销售人员也会提供更大的折扣,以快速增加销售量。
这两个方式并不能都保证利润成正比增长,而利润往往是企业最看重的。
这便是“古德哈特定律”:指标变成目标后,就不再是一个好的指标。
如果某个指标附加有足够多的奖励,人们就会想方设法地提高自己的得分,而这样做就会削弱该指标原本的评估价值。正是量化指标本身改变了需要量化的对象的行为。
还有一种更接近纯粹胡扯的现象——数学滥用,而且它并不罕见。
数学滥用(Mathiness)指的是那些看起来都像是数学表达式的东西,但它们和数学可以说是毫无关系。
比如信任方程:

按照这个方程,当自利感降到最低时,信任度就会非常高,那么我们是不是应该根据抛硬币的结果决定一切呢?毕竟硬币真实可靠又不会自私自利。
又如“一年中最悲伤的一天”(一月的第三个星期一)的公式:
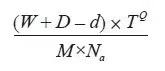
W代表天气,d代表债务,T代表圣诞节以来的时间,Q代表放弃新年决心以来的时间,M代表干劲不足,Na代表采取行动的必要性。(不清楚D在公式中代表什么。)
看起来多么像是一种严谨的数学方法!但它到底是什么意思呢?这些量如何测量,单位又是什么?如果只是要表达正相关还是负相关,那么大可不必采取这种形式,它不但无用,还会让人费解。
数据胡扯,科学领域也不能幸免
是的,科学领域也会屡屡中招。
还记得古德哈特定律吗?“指标变成目标后,就不再是一个好的指标。”在科学领域,使用引文指标来衡量期刊质量已经导致编辑钻制度空子。
有的期刊会在1月份发表更多文章,这样一来,这些文章本年度被引用的机会就会增加。所有这些反常的行为都违背了期刊的使命,削弱了引用数作为质量指标的有效性。
类似地,对科研人士的论文数量指标催生了只要给钱便可发表文章的“掠夺性期刊”,也让科研领域成为了胡扯的高发地带。
虽然掠夺性期刊的主要客户是给简历增色的边缘学术人,但也包括气候怀疑论者、反对疫苗者、神创论者和艾滋病否认论者。
他们以版面费为代价换取在科研领域的“一面之地”,然后说他们的边缘信仰通过了“同行评议”的科学。这是典型的胡扯污染。

作为读者,我们没有任何万无一失的方法,可以确定无疑地知道一篇科学论文是否完全正确。但伯格斯特龙和韦斯特提醒我们,至少要保持合理的怀疑,这是辨别胡扯的第一步。
比如注意论文中的论断与它是在哪儿发表的是否相匹配,尤其要警惕低层次期刊上出现的异乎寻常的论断。
拆穿胡扯,你需要一些技巧
辨别可能的胡扯的最终目的,是指斥胡扯。
然而清除胡扯的代价要远远高于制造胡扯,哪怕真正符合科研方法论的论文也是如此。
伯格斯特龙和韦斯特就借助一个精彩的驳斥案例,反证了这种“高端胡扯”的屏蔽性与危险。他们给这种方法取名为“令人难忘驳斥法”。

这个令人难忘的针对功能磁共振成像技术(fMRI)的驳斥出现在一次神经科学会议上。
fMRI能够帮助神经科学家探索哪些大脑区域参与了哪些认知,典型的研究会比较对象和对照组的fMRI图像,并思考为什么大脑的某些部分亮度有所不同。
但是,实验软件必须对评估结果的统计学意义做出假设。而最近的一项研究表明,这些假设有时会严重夸大差异。问题已经暴露,但科学家们并未对这个问题的严重性达成一致。
于是一份标题为《通过死大西洋鲑鱼研究人类神经活动:论多重比较校正的重要性》的学术墙报登场了。你没看错:一条死鲑鱼。
这是一个故意为之的愚蠢实验。研究人员跟那条死鱼交谈,还给它看了人们在不同社交环境中的照片。结果令人震惊。当鲑鱼被问及人们的情绪时,影像显示它脑干的几个区域表现出来的活跃性高于它在“休息”时的活跃性。
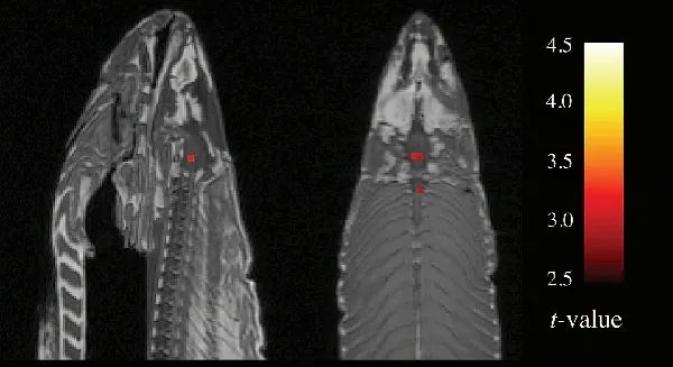
这还只是对人类社交场景的“反应”,想象一下,如果这条鲑鱼被问及鲑鱼的情绪,这些区域会多么明亮。
要么是我们在死鱼认知方面取得了惊人发现,要么是我们未经修正的统计方法出了问题。
指斥胡扯不只是为了增强自信,它还是一种道义上的责任。正如我们在开头所说,世界充斥着各式各样的胡扯,有些是无伤大雅的,有些是小麻烦,还有一些甚至很有趣,但很多胡扯会给科学的诚实和生死攸关的决策带来严重的后果。
“数据成了新式胡扯者的杀手锏”。但我们绝不否认科学是理解物理世界的一个成功的标准手段。不管我们抱怨什么,不管我们发现了什么偏见,不管我们遇到什么问题,不管我们说了什么废话,科学最终还是会成功的。
部分内容摘编自《拆穿数据胡扯》,中信出版社出版。

原标题:《大数据算法天花乱坠的时代,如何识别“数据陷阱”?》



