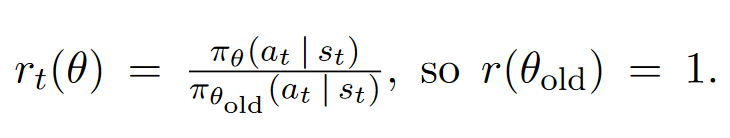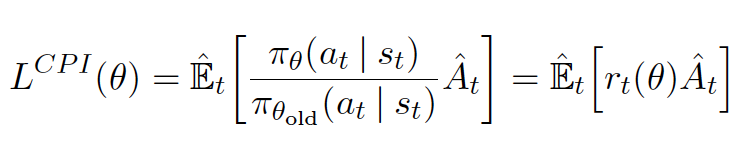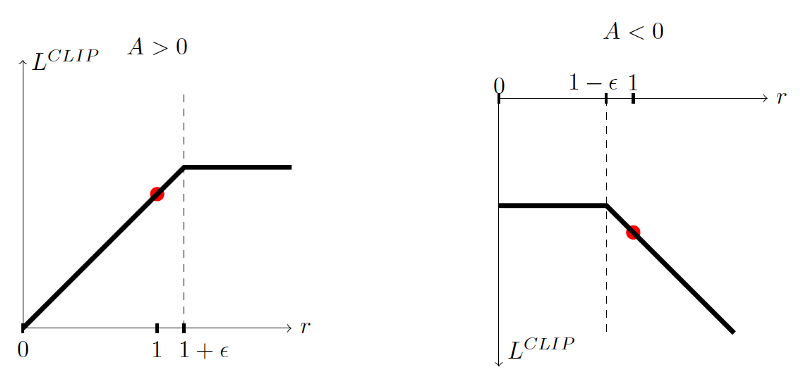翻译 | 安石徒校对 | 斯蒂芬•二狗子
审核 | 邓普斯•杰弗 整理 | 菠萝妹
原文链接:
https://towardsdatascience.com/proximal-policy-optimization-ppo-with-sonic-the-hedgehog-2-and-3-c9c21dbed5e
深度强化学习从入门到大师:以刺猬索尼克游戏为例讲解PPO
(第六部分)
几周前,OpenAI在深度强化学习上取得了突破性进展。由5个智能体的组成的人工智能团队OpenAI five击败了现实中的DOTA2玩家。但遗憾的是,该人工智能团队输掉了随后的第二场比赛。
Dota2
这个突破性进展的取得得益于强大的硬件支持和 PPO 算法(近端策略优化 Proximal Policy Optimization)。
PPO的核心思想是避免采用大的策略更新。为此,我们采用变化率表明新旧策略的不同,并缩减该变化率在0.8到1.2之间以保证策略更新不大。
此外,PPO的另一项创新是在训练智能体的k个epochs过程中使用了小批量梯度下降法。你可以读我们之前已经实现的这篇文章 A2C with Sonic The Hedgehog。
今天,我们将深入了解PPO结构,并应用PPO来训练智能体学习玩刺猬索尼克系列1,2,3。
但是,如果想要理解好PPO,你首先需要掌握A2C( 建议先阅读上一篇文章简单介绍A2C (第五部分))
策略梯度(PG)目标函数存在的问题
曾记否,在学习策略梯度时,我们了解了策略目标函数(或策略损失函数)。
PG的思想是采用上面的函数一步步做梯度上升(等价于负方向的梯度下降)使智能体在行动中获取更高的回报奖励。
然而,PG算法存在步长选择问题(对step size敏感):
步长太小,训练过于缓慢
步长太大,训练中误差波动较大
面对训练过程波动较大的问题时,PPO可以轻松应对。
PPO近端策略优化的想法是通过限定每步训练的策略更新的大小,来提高训练智能体行为时的稳定性。
为了实现上述想法,PPO引入了一个新的目标函数“Clipped surrogate objective function”(大概可以翻译为:裁剪的替代目标函数),通过裁剪将策略更新约束在小范围内。
裁剪替代目标函数 Clipped Surrogate Objective Function
首先,正如我们在stackoverflow中的解释,我们不采用智能体行动的对数概率logπ(a|s)(vanilla policy gradient method )来跟踪智能体行动的效果,而是使用当前策略下的行动概率(π(a|s))除以上一个策略的行动概率 (π_old(a|s))的比例:
摘自PPO论文:PPO paper
如上所示,rt(θ)表明了新旧策略间概率比:
若 rt(θ)>1,则当前策略下的行动比原先策略的更有可能发生。
若 rt(θ)⊂(0,1),则在当前策略下行动发生的概率低于原先的。
据此,新的目标函数可如下所示:
摘自PPO论文:PPO paper
但是,如果你当前策略的行动的可能性远高于之前策略的情况下,此时不对目标函数进行约束, 那么 rt(θ)的值就会非常大,还会导致PG采取可能破坏策略的大梯度更新。
因此,需要对目标函数进行约束,惩罚那些导致rt(θ)远离1的变化(本文中比率仅允许在0.8和1.2之间),这样可以确保不会发生大的策略更新。
为此,我们有两个解决方案:
TRPO(Trust Region Policy Optimization,置信区间策略优化)采用的KL散度来约束策略更新(注:使用目标函数之外的KL散度,来约束需要更新的策略数目,以保证梯度单调上升;此外还有其他方法,例如ACER,Sample Efficient Actor-Critic with Experience eplay)。但是TRPO这种方法使用起来过于复杂,且耗费更多的计算时间。
使用PPO优化的裁剪替代目标函数。
裁剪替代目标函数
通过该函数,得到两个概率比,一个非裁剪的和一个裁剪的(在[1 - ?, 1+?]区间,?是一个帮助我们设置范围的超参数,本文中? = 0.2)。
然后,我们选择裁剪和非裁剪中的最小值,最终得到的值范围是小于非裁剪的下界的区域。
为此,我们需要考虑两种情况case:
摘自PPO论文
case 1: 当优势A>0
如果Ȃt > 0,即该行动好于在该状态下的行动得分的平均值。因此,我们应鼓励新策略增加在该状态下采取该行动的概率。
也就增加了概率比r(t),增加了新策略的概率( At* 新的策略概率),同时令分母上的先前策略保持不变。
因为进行了裁剪,所以rt(?)最大只能增长到1+ ?。这意味着当前行动概率相较于原先策略不可能上百倍地提高。
为什么要这样做?因为我们不想过度更新策略。在该状态下采取这个行动的估计结果只是一次尝试的得出结果,并不能证明这个行动总是有较高的正向回报(说白了,防止陷入局部最优值),因此,我们就不要贪婪地学习,以防止智能体选择糟糕的策略。
总而言之,在(行动对结果)是积极作用的情况下,需要(在这步梯度上升中)增加一点该行动的概率,但不是太多。
case 2:当优势A<0
如果Ȃt < 0,即该行动为导致消极结果的行动,应该被阻止。因此概率比rt(?)会被减少。但同时进行裁剪,使rt(?)最小只能将降低到1- ?。
同样,我们不想最大化减少该行动被选中的概率,因为这种贪婪学习会导致策略过大的改变,以至于变得糟糕也说不定。
总而言之,多亏裁剪替代目标函数,我们约束了新策略相对旧策略两种情形下的变动范围。于是,我们把概率比控制在小区间内,因此,这种裁剪有利于求策略梯度。如果概率在[1 - ?, 1+?]区间外,梯度值为0。
最终的裁剪替代目标损失函数:
使用PPO优化的A2C类型智能体学习玩索尼克系列游戏
现在,我们将准备实现一个A2C类型的PPO智能体。A2C类型训练包括该文中所述的A2C过程。
同样,这个代码实现比以前的代码要复杂好多。我们要开始复现最先进的算法,因此需要代码的更高的效率。这也是为什么,我们将整个代码分为不同对对象和文件来实现。
为了实现一个PPO智能体,需要读一读如下包含完成PPO过程的笔记和代码解释:
(((0)))(((1)))
如上所述,你已经创建了一个学习如何玩刺猬索尼克系列游戏1,2,3的智能体。太棒了!一个好的智能体需要在一个GPU上训练10到15小时。
别忘了自己亲自实现代码的每一个部分,因为调试完善代码是非常重要的。尝试更改环境,调整超参,尝试是学习的最佳途径也是最大乐趣。
花点时间来想想我们从第一节课到现在取得的所有成就:从简单的文本游戏(OpenAI taxi-v2)到像毁灭战士、索尼克这些复杂的游戏,我们采用越来越强大的模型结构。这真是极好的!
下一回,我们将学习深度强化学习中最有趣的的新内容之一——好奇心驱动的学习。
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击【深度强化学习从入门到大师:以刺猬索尼克游戏为例讲解PPO(第六部分)】:
https://ai.yanxishe.com/page/TextTranslation/1408
【点击查看本系列文章】
深度强化学习从入门到大师:简介篇(第一部分)
深度强化学习从入门到大师:通过Q学习进行强化学习(第二部分)
深度强化学习从入门到大师:以Doom为例一文带你读懂深度Q学习(第三部分 - 上)
深度强化学习从入门到大师:进一步了解深度Q学习(第三部分 - 下)
深度强化学习从入门到大师:以 Cartpole 和 Doom 为例介绍策略梯度 (第四部分)
深度强化学习从入门到大师:简单介绍A3C (第五部分)
AI研习社每日更新精彩内容,观看更多精彩内容:雷锋网雷锋网雷锋网
7分钟了解Tensorflow.js在Keras中理解和编程ResNet初学者怎样使用Keras进行迁移学习如果你想学数据科学,这 7 类资源千万不能错过
等你来译:
深度学习目标检测算法综述一文教你如何用PyTorch构建 Faster RCNN高级DQNs:利用深度强化学习玩吃豆人游戏用于深度强化学习的结构化控制网络 (ICML 论文讲解)