参与:李诗萌、Nurhachu Null、刘晓坤
了解人们如何使用他们的设备有助于改善用户体验。但是,访问此类数据(例如用户在键盘上键入过的内容以及访问的网站)可能会损害用户的隐私。苹果开发了一个系统架构,利用客户隐私的本地差异,结合现有的隐私最佳处理做法,实现了规模化学习。
我们设计了高效且可扩展的本地差别隐私算法(local differentially private algorithm),并严格分析了设备效果、用户隐私、服务器以及设备带宽之间的权衡。了解这些因素并平衡它们,我们即可成功地使用本地差别隐私算法进行部署。这种部署可以扩展到数以亿计的用户以及多种应用,例如识别流行的表情符号、用户健康数据、以及 Safari 中的媒体播放偏好。
我们在完整版本中提供有关该系统的更多详细信息。(https://machinelearning.apple.com/docs/learning-with-privacy-at-scale/appledifferentialprivacysystem.pdf)
介绍
深入了解用户对提升用户体验而言至关重要,但所需数据隐私且敏感,因此必须保密。除了隐私的问题之外,要实际应用使用这些数据建立的学习系统还要考虑资源开销、计算成本以及通信成本。我们在本文概述了一种系统架构,它结合了差别隐私和从用户群体中学习用户行为的隐私最佳实践。
差别隐私(differential privacy)[2] 从数学角度严格定义了隐私,这也是保护隐私最有力的保障之一。这种想法的基础在于仔细校准噪声可以隐藏用户的数据。用户提交数据后,噪声平均值提高,并从中产生了有意义的信息。
在差别隐私框架内,有两个环境:中央环境和本地环境。在我们的系统中,我们收集的并不是中央隐私差别框架中所必须服务器上的原始数据,因此我们采用了本地隐私差别,这是一种高级的隐私形式 [3]。本地差别隐私的优势在于,在将数据发送给设备之前进行了随机化处理,因此服务器不会得到原始数据。
我们有意将该系统设计为可选择且公开的。在用户明确选择报告用法信息之前,系统不会记录或传输数据。例如当用户输入表情符号时,使用本地模型的事件级差别隐私 [4] 将数据在用户设备上私有化。另外,我们会限制每次传输个人事件的数量。数据通过每天一次的加密通道传输到服务器,且数据在传输过程中没有设备标识符。数据记录到达访问受限的服务器时会立刻失去其 IP 标识符,同时会立即失去与其他记录间的关联。从这一点讲,我们无法对数据进行区分,例如,我们无法确定表情记录和 Safari 网络域记录是否来自同一个用户。我们计算并统计这些记录,得到的汇总数据将在内部与苹果的相关团队共享。
我们专注于估算元素频率的问题——例如,表情符号和网络域名。在估计元素的频率时,我们会考虑两个子问题。首先,我们从已知的元素字典中计算直方图。其次,当元素字典未知时,我们希望得到数据集中出现最频繁的元素的列表。
系统架构
我们的系统由设备端和服务器端数据处理组成。在设备端,数据私有化阶段(privatization)会确保原始数据是有差别的隐私数据。具有访问权限的服务器会对这些数据进行处理。数据的处理阶段可以进一步分为内容提取(ingestor)和内容整合(aggregation)阶段。我们会在下面详细解释每个阶段。
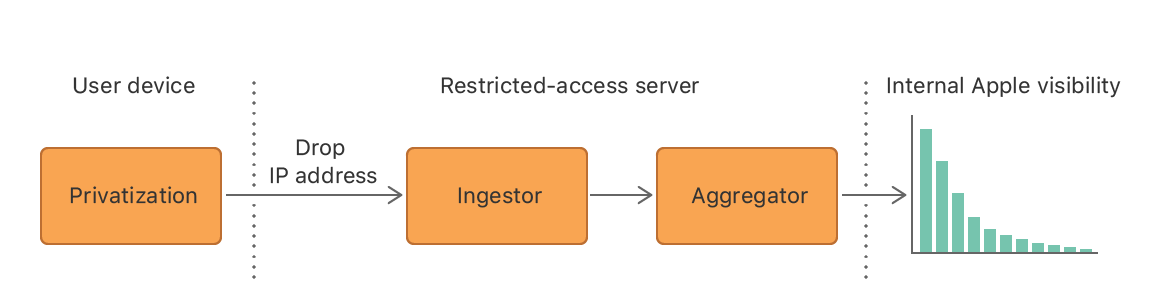
图 1: 系统概貌
私有化阶段
用户可在 macOS 的「系统偏好设置」或 iOS 设置中选择是否共享隐私数据以供分析。对于未加入该计划的用户,系统保持休眠状态。对选择共享数据的用户,我们将ϵ定义为每个事件的隐私参数。此外,我们对每个使用案例每天可以传输的隐私数据的数量进行了限制。我们是以每个用例隐私特性的基础数据集为基础选择的ϵ。这些值与差别隐私研究社区提出的参数一致,如 [5] 和 [6]。此外,下文提出的算法通过哈希碰撞(hash collisions),对数据进一步加密。我们还通过删除服务器中的用户标识符和 IP 地址来加强数据保密力度,这些服务器中的记录按用例分隔开,因此多个记录之间也不存在关联。
无论何时在设备上发生事件,数据都会立即通过ϵ——本地差别隐私进行私有化,并使用数据保护 [1] 临时存储在设备上,而非立即上传到服务器上。系统根据设备情况进行延迟后,会根据上述限制从差别隐私记录主体中随机抽取样例,并将采样记录发送给服务器。这些记录不含设备标识符或事件发生时间的时间戳。设备和服务器之间的通信使用 TLS 进行加密。参见图 2。
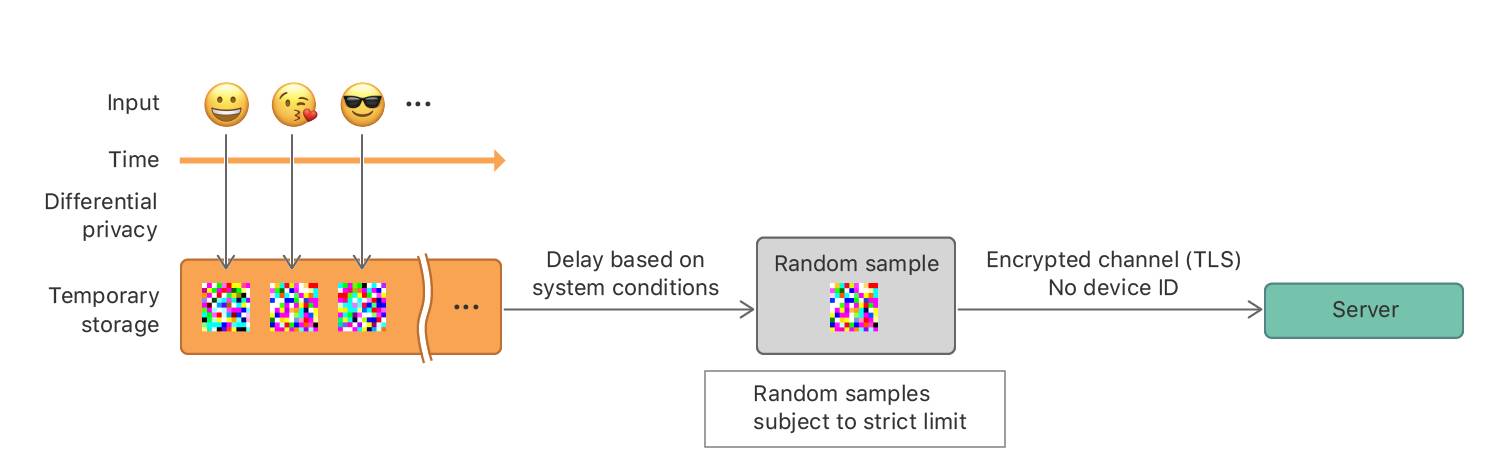
图 2:私有化阶段
在 iOS 上,可以在「设置」>>「隐私」>>「分析」>>「分析数据」中见到以「差别隐私」开头的条目,在该条目下可找到这些记录。而在 macOS 上,这些记录可以在「系统报告」的「控制台」中见到。图 3 是使用该算法计算流行表情符的样本记录。该记录还列出了算法参数,参数问题会在本文后面的部分叙述,私有化的数据条目以十六进制字符串表示。注意,这里并未提供完整的私有化数据,本例中完整字符大小应该是 128 字节。

图 3:私有化记录示例报告
提取与整合阶段
在提取器处理前,要先去除隐私记录的 IP 地址。此后提取器会收集所有用户数据并进行批量处理。批处理的过程会删除元数据,例如收到隐私记录的时间戳,并根据用例分离这些记录。在将输出转到下一个阶段之前,提取器会随机排列每个用例中的隐私记录。
整合器从提取器获得隐私记录,并根据下文描述的算法为每个用例生成一个差别隐私直方图。计算统计数据时不会将多个用例的数据合并。在这些直方图中,只含有计数超过规定阈值 T 的域元素。这些直方图将与苹果的相关团队在内部共享。
算法
我们接下来会描述三个本地差别隐私算法。
隐私计数平均值草图
CMS 算法(Private Count Mean Sketch)整合设备提交的记录,并在域元素字典中输出计数直方图,同时保留本地差别隐私。这一过程包含两个阶段:先是客户端处理,之后是服务器端整合。
我们用一个例子来说明这个过程。假设用户访问网域 ,客户端算法从一组备选哈希函数 {h_1,h_2,h_3,…,h_k} 中随机采样,得到一个哈希函数,并用选定的哈希函数(比如 h_2)将该网域编码为一个大小为 m 的小空间。令 h_2()= 31。这种编码被写作一个大小为 m 的独热向量,该独热向量的第 31 位被设置为 11。为了确保差别隐私,独热向量的每一位的独立翻转概率为 1/(e^(ϵ/2)+1),其中ϵ是组成隐私向量的隐私参数。之后,独热向量和选择的哈希函数索引会被发送到服务器。
服务器端算法通过整合来自设备的隐私向量来构造草图矩阵 M。该矩阵有 k 行——每个哈希函数对应一行,还有与从客户端发送的向量大小对应的 m 列。
当记录上传到服务器上的时候,该算法会将隐私向量加到第 j 行的向量上,其中 j 是设备采样的哈希函数的下标。然后 M 的值会进行适当缩放,从而每一行都能帮助对每个元素的频率进行无偏估计。
为了计算网域 出现的频率,该算法通过将向量 j 的每行读为 M [j,h_j()],得到无偏估计,并计算这些估计值的平均值。在本文的完整版中,我们证明了隐私计数误差(或方差)的解析表达式,这使得我们可以使用合理的方式在获得准确计数的同时使资源开销最小化,如设备带宽和服务器运行时间。
隐私 Hadamard 矩阵计数均值草图
我们在这篇文章的完整版中描述了增加设备的带宽是如何在 CMS 中带来更准确的计数的。但是,这也给用户带来了更高的传输成本。我们希望在减少传输成本的同时把对准确度的影响最小化。所以我们设计了隐私 Hadamard 矩阵计数均值草图算法(Private Hadamard Count Mean Sketch,HCMS),它的优点是设备发送比特信息的时候,准确度的损失很小。有了 HCMS,就有可能让用户不用付出很高的传输代价就可以实现合理的准确计数。我们在本文的完整版中把使用 HCMS 得到的准确度进行了量化。
我们现在以一个例子解释 HCMS 算法。假设用户访问了这个网站: 。与在 CMS 中一样,客户端算法会从一系列备选哈希函数 {h_1,h_2,h_3,…,h_k} 中选择一个随机哈希函数,然后使用所选的哈希函数(例如 h_3)将这个域名编码成一个小空间。令 h_3()=42。这个编码被写成了独热向量的形式:v=(0,0,…,0,1,0,…,0,0)。其中 1 在索引为 42 的位置。因为我们想传输一个比特,所以通常的方法就是从 v 中随机选择一个坐标并发送。但这会显著地增加直方图中的误差(或方差)。为了减小方差,我们在给 v 使用一次 Hadamard 基变换,例如,v′ =Hv=(+1,−1,…,+1)。为了确保差别隐私,从 v′中采样单个随机坐标,然后对应的比特以 1/(e^ϵ+1) 的概率进行翻转。发送到服务器的输出包括所选哈希函数的索引、采样坐标的索引以及隐私比特:如图 4 所示。
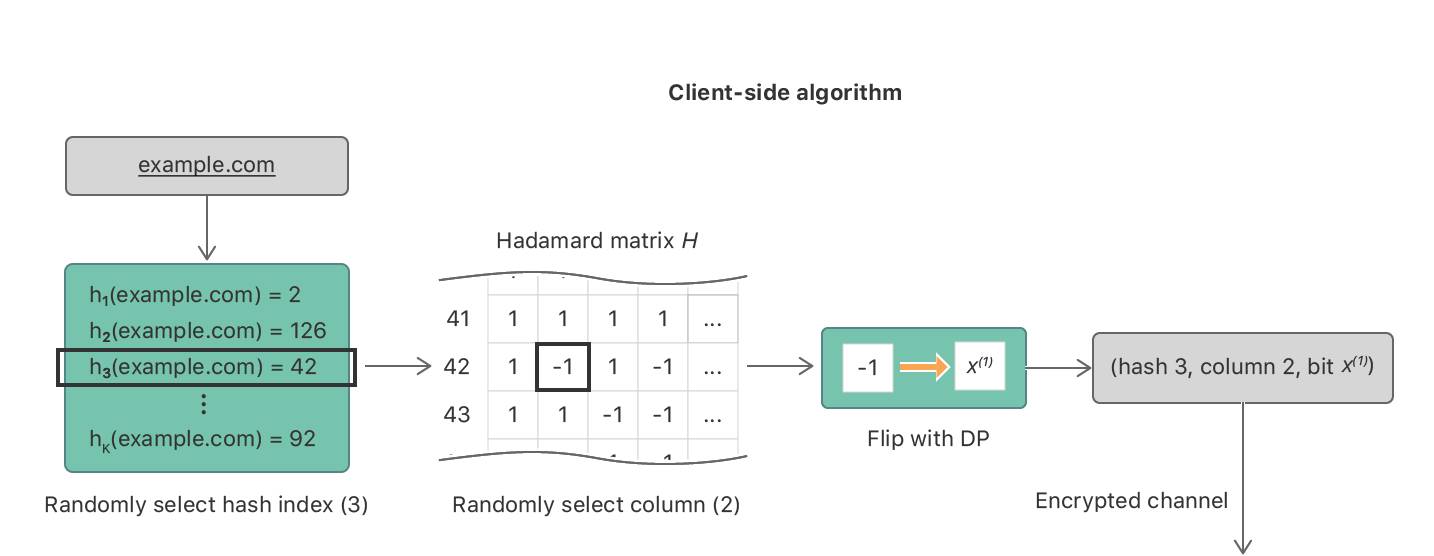
图 4:客户端的 HCMS 算法
与 CMS 类似,服务器端的算法使用一个叫做草图矩阵 M 的数据结构来聚合来自客户的隐私向量。矩阵 M 的行代表的是备选哈希函数的索引。此外,列代表的是设备采集到的随机坐标的索引。矩阵的第(j,l)个元素表示设备选择第 j 个哈希函数 h_j、采样第 l 个随机坐标之后提交的隐私向量。此外,隐私向量被适当扩展,且使用转置 Hardamard 矩阵将 M 转换为初始的基。在这个阶段,矩阵的每一行有助于提供一个元素的频率的无偏估计。为了计算域名 的频率,这个算法首先会通过读取第 j 行(M[j,h_j()])从 M 的每一行得到一个估计。最后一步,如图 5 所示,这个算法会计算这 k 个估计的平均值,,以减小方差。
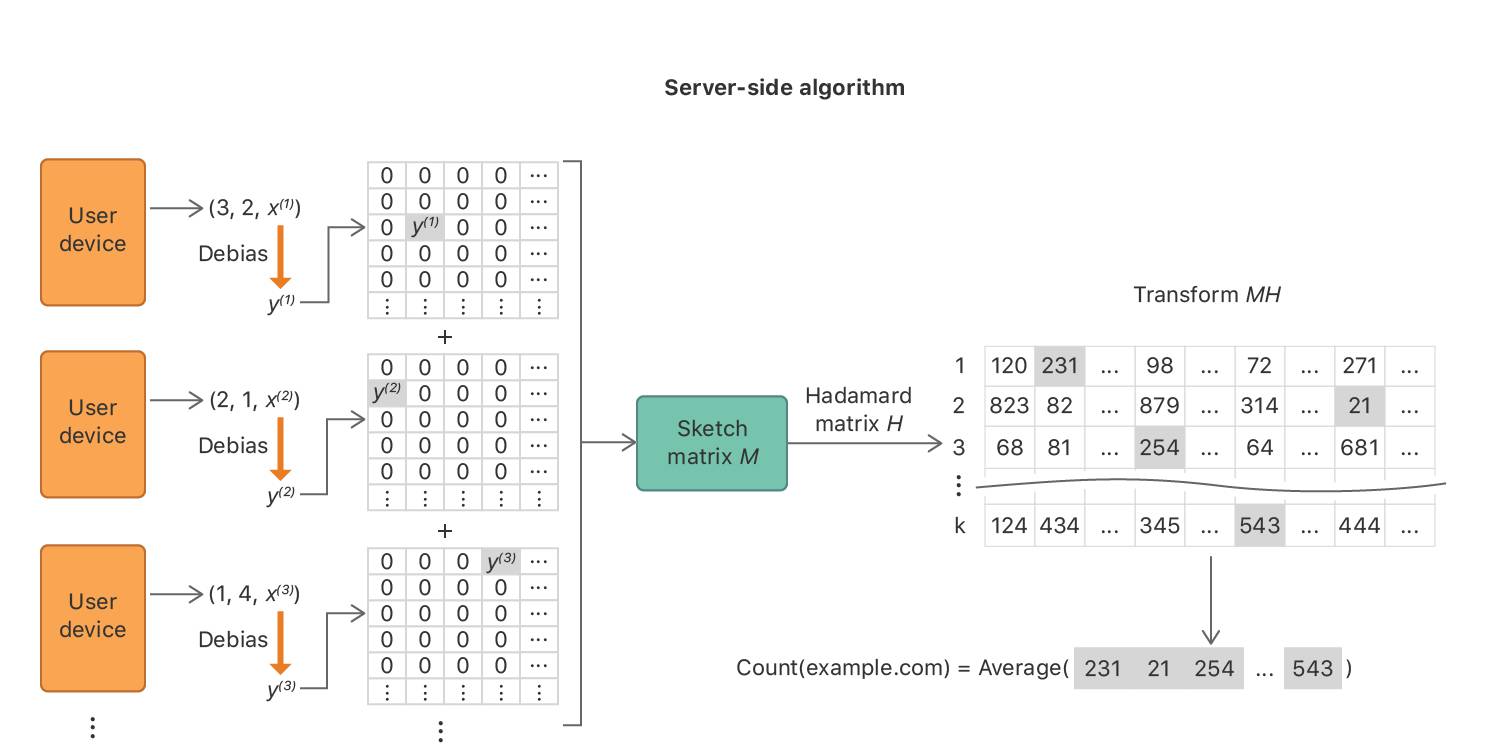
图 5:服务器端计算 HCMS 的算法。
隐私序列碎片拼图
为了确定对应的计数,前面的算法都假设存在一个已知的关于域名的字典,服务器可以通过枚举这个字典来确定对应的计数。但是,在实际的用况中,域名是海量的,在全空间枚举这些域名的计算成本是极其昂贵的。例如,在发现频繁输入的新词时,即使我们将空间限制在 10 个字母的区分大小写的英文单词,这种方法也需要服务器在至少 5210 个元素中循环。
与此不同的是,我们开发了一个叫做序列碎片拼图(sequence fragment puzzle,SFP)的算法,并在发现新单词的任务设置中使用了这个算法。我们利用了这么一个事实:对于某一个流行的字符串,它的任何一个子字符串也是流行的。在设备上,我们使用设备端的 CMS 算法来把输入的单词私有化。另外,我们选择了这个单词的一个子串,并将该子串与这个单词的一个 8 比特的哈希拼接在一起。我们将这个小的哈希作为拼图(puzzle)片段,将与这个哈希拼接在一起的子串称为碎片(fragment)。这个碎片通过 CMS 算法进行了私有化处理,并且它还能够和私有化的单词一起被传输到服务器。例如,如果一个单词是 Despacito,被选中的子串是 sp,那么,客户端会发送三个内容:CMS(Despacito)、CMS(sp||97),其中 97 就是拼图片段,以及被选择的子串的位置。
利用碎片的草图,服务器端的算法会得到关于每个子串位置的所有可能碎片的直方图。由于来自同一个单词的所有碎片会有着同样的拼图片段,所以拼图片段允许服务器关联来自同一个单词的碎片。然后,通过限制在最流行的片段上之后,通过拼接和拼图片段相匹配的流行碎片,服务器算法会确定出一个待选字符串的列表。待选字符串的集合形成了一个具有合理大小的字典,从而可以让我们在所有单词上使用 CMS 算法。
结果
我们在下面展示了三个用况来描述我们的算法是如何在保护用户隐私的同时增强产品功能的。
发现流行表情包
给定表情库上所有表情包的流行度之后,我们希望能够确定哪些特定的表情包是最常被用户使用的,以及这些使用度有怎么样的特征分布。为此,我们部署了我们的算法来理解不同语言环境(keyboard locales)的表情包分布。对这个用况而言,我们设置的 CMS 参数是:m=1024,k=65536,ϵ=4,以及具有 2600 个表情包的字典。
数据展示出了不同语言环境的诸多区别。在图 6 中,我们观察了两个语言环境的快照:英语和法语。使用这个数据,我们可以提升我们在不同语言环境的表情包预测。
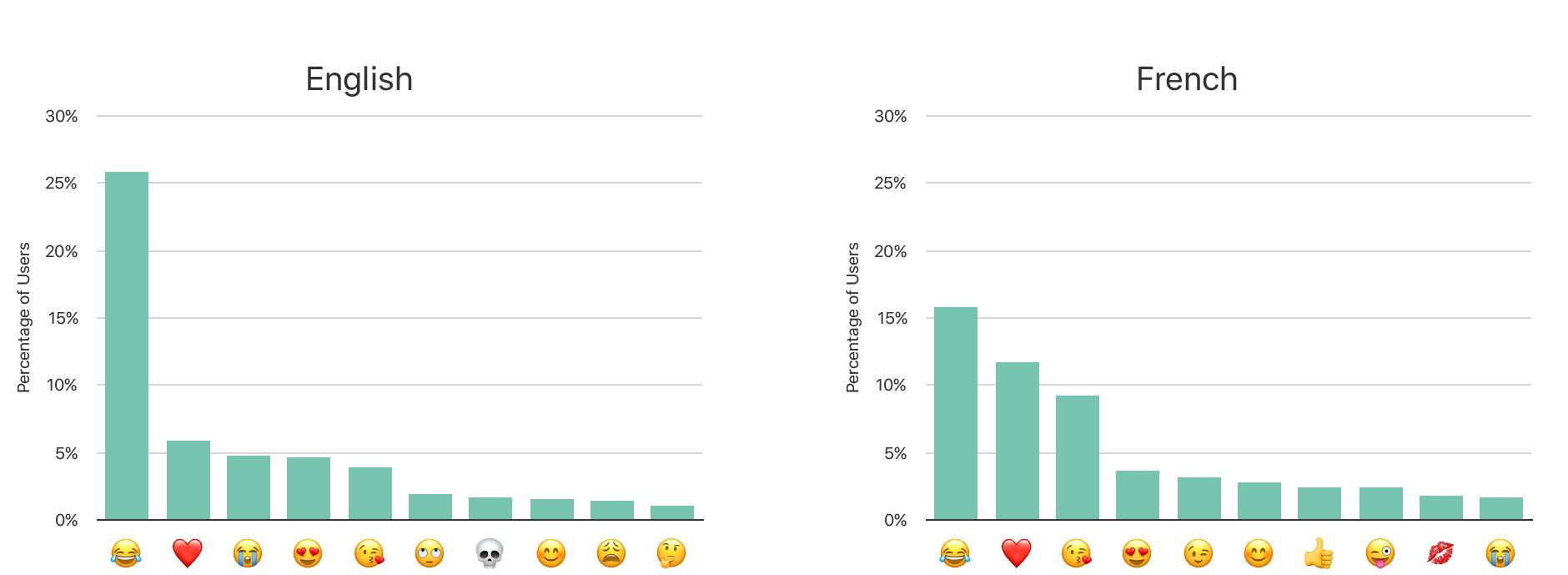
图 6:不同语言环境的表情包
鉴别 Safari 中高耗能和高内存使用
有些网站的资源是特别密集的,我们希望能够分辨出这些网站以确保更好的用户体验。我们考虑了两种类型的域:导致高内存使用的网站,以及那些由于 CPU 占用率高而特别耗电的网站。在 iOS11 和 macOS High Sierra 中,Safari 可以自动地检测这些异常的网站,并且使用差别隐私进行报告。
使用我们的算法,我们能够确定哪些域名具有较高的资源消耗。我们对这个用况设置的 HCMS 参数如下:m=32768,k=1024,ϵ=4,以及具有 25000 个域名的字典。需要记住,差别隐私记录在 HCMS 中仅仅记录成了 1 个比特。我们的数据显示,最常见的、消耗资源的域名包括视频网站、购物网站和新闻网站。
发现新单词
为了提升自动更正功能,我们希望能够学习那些不在设备本地字典中的单词。为了发现新单词,我们部署了上面提到的 SFP 算法。
这个算法可以生成多种语言的结果,包括英语、法语和西班牙语。例如,针对英语语言环境学习到的单词可以被分成多个种类:类似 wyd、wbu、idc 的缩写;类似 bruh、hun、bae,以及 tryna 的流行表达;类似 Mayweather、McGregor、Despacito、Moana,以及 Leia 节令性的词语;类似 dia、queso、aqui,以及 jai 的外语词语。使用这些数据,我们可以不断地更新设备上的字典,以提升输入法体验。
我们发现的另一类单词是没有以 e(th 或 lov) 和 w(kno) 结尾的位置单词。如果用户意外地按下了键盘上最左边的预测单元(它包含目前输入的所有词的预测),一个额外的空格键会加在当前输入词后面,而不是他们想要输入的字母。这是我们通过本地差别隐私算法可以学到的关键洞察。
结论
在这篇文章中,我们提出了一个新颖的学习系统架构,它利用本地差异隐私并将它与最佳隐私体验结合起来。为了将我们的系统扩展到上百万的用户,以及很多种用况中,我们针对已知和未知的字典配置开发了本地差别隐私算法——CMS、HCMS,以及 SFP。在我们的完整版文章中,我们对这几种不同的因素的权衡做了解析的表达,包括隐私(privacy)、效用(utility)、服务器计算负载(server computing overhead),以及设备带宽(device bandwidth)。效用理论给出了为了最小化传输代价,并且不对准确度产生严重影响的算法参数选择的基本方式。如果没有这种表达,评价对准确度的影响将会很困难,例如,传输成本是否在运行代价高昂的迭代中得到了降低。更进一步,为了将传输成本保持在绝对的最小值,我们的 HCMS 算法可以在每个用户仅仅发送一个隐私比特的时候就能得到准确的计数。我们相信我们的论文是首次在实际中的多种用况设置中成功地部署差别隐私算法 [7]。我们已经证明,我们能够在满足本地差异隐私的前提下,发现常用的缩写和键入的俚语、流行的表情包、健康数据。此外,我们还能够鉴别过分消耗资源和电量的网站,以及用户希望自动播放的网站。为了得到最佳用户体验,这个信息已经被用来改善产品功能。
希望我们的工作能够弥补隐私系统中理论和实践之间的差距。同时也希望我们的工作能够持续支持大规模广发学习问题上的研究,同时能够保障用户的隐私。
参考文献
[1] https://www.apple.com/business/docs/iOS_Security_Guide.pdf.
[2] C. Dwork, F. McSherry, K. Nissim, and A. Smith. Calibrating Noise to Sensitivity in Private Data Analysis. TCC, 2006.
[3] C. Dwork and A. Roth. The Algorithmic Foundations of Differential Privacy. Foundations and Trends in Theoretical Computer Science, 2014.
[4] C. Dwork, M. Naor, T. Pitassi, and G. N. Rothblum. Differential Privacy Under Continual Observation. Proceedings of the Forty-second ACM Symposium on Theory of Computing, 2010.
[5] G. Fanti, V. Pihur, and Ú. Erlingsson. Building a RAPPOR with the Unknown: Privacy-Preserving Learning of Associations and Data Dictionaries. PoPETS, 2016.
[6] Z. Qin, Y. Yang, T. Yu, I. Khalil, X. Xiao, and K. Ren. Heavy Hitter Estimation Over Set-valued Data with Local Differential Privacy. Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, 2016.
[7] Ú. Erlingsson, V. Pihur, and A. Korolova. RAPPOR: Randomized Aggregatable Privacy-Preserving Ordinal Response. Proceedings of the 21st ACM Conference on Computer and Communications Security, 2014.
原文链接:https://machinelearning.apple.com/2017/12/06/learning-with-privacy-at-scale.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



